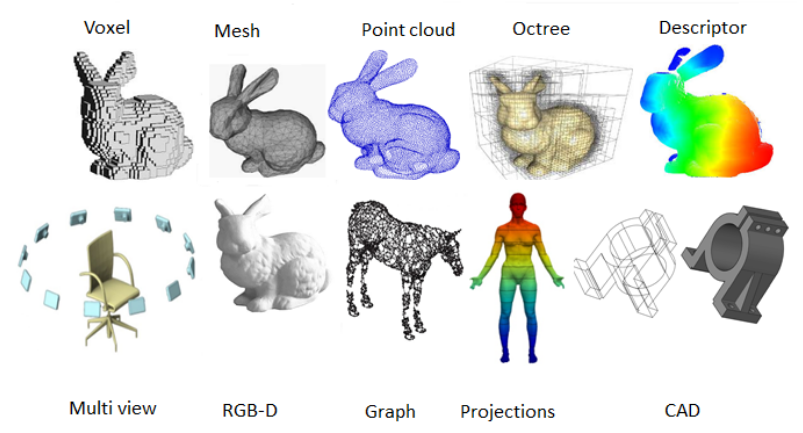
今天刚好阅读到一篇关于3D表征的综述论文,想借此机会梳理下之前接触的一些论文,同时也趁此机会查缺补漏。3D Representation Methods: A Survey
这篇文章的主题是对不同3D表征的简要介绍,后续会分别对各个表征方式开个专题,介绍下代表性的论文,以及一些延申的方法。同时也根据这篇综述,介绍下推动该领域发展至关重要的重要数据集。
3D 表示方法的演变以从基本几何结构发展为复杂的数据驱动模型。
1. Voxel Grid
体素网格表示是一种对3D对象进行建模的方法,其中空间被划分为规则的立方体网格,称为voxels。网格中的每个体素都可以存储颜色、密度或材料属性等信息,从而允许对对象进行详细的体积表示。该技术特别有利于表示复杂的几何图形和内部结构,而这些几何图形和内部结构可能难以使用基于表面的方法(如网格)进行捕获。

- VoxNet: 这是一个直接在体素网格上执行对象识别任务的三维卷积神经网络(CNN)。该方法证明了将体素表示与深度学习技术相结合,在三维形状分类和识别任务中实现最先进性能的潜力。
- VoxGRAF: 提出了一种使用稀疏体素网格进行三维感知图像合成的新方法。他们的研究通过有效地将稀疏体素网格与渐进增长、自由空间修剪和适当的正则化等复杂技术相结合,证明了用三维卷积替代整体多层感知器(MLP)的可行性。这种方法不仅确保了从任意视角的高效渲染,还保证了合成图像中的三维一致性和高视觉保真度,标志着图像合成和渲染领域的一大飞跃。
- Vox-E: 探索了由文本描述指导的三维物体体素编辑领域。这项创新工作引入了一种直接在三维空间中操作的体积正则化损失,利用体素表示的显式特性来强制原始物体和编辑后物体的全局结构之间的相关性。这一进展为三维建模和编辑领域开辟了新的视野,其中可以通过自然语言输入直观地指导详细且深入的修改,从而提高了三维物体操作的可用性和灵活性。
2. Point Cloud
点云本质上是空间中的数据点集合,代表物体或场景的外表面。这些点通常由其在三维空间(x, y, z)中的坐标定义,有时还包括颜色、强度和法向量等附加信息。点云的关键优势之一是它们的简单性和对三维世界的直接表示。与其他三维表示方法(如网格或体素网格)不同,点云不需要连接信息或体积数据,因此更容易生成和操作。然而,这种简单性也带来了挑战。点云通常稀疏、无结构且可能包含噪声,这使得分割、识别和重建等处理任务更加复杂。

- PointNet: 提出了一种新颖的神经网络架构,该架构可以直接处理点云,无需将其转换为体素网格或网格等结构化形式。这项工作表明,深度学习模型可以通过考虑点集的置换不变性,并使用一系列共享的多层感知器(MLPs)和最大池化来聚合全局特征,从而在三维识别任务上实现卓越的性能。
- PointNet++ : 通过引入层次学习扩展了原始的PointNet,使网络能够捕获多个尺度的局部结构。这种方法显著提高了处理不同点密度和捕获精细几何细节的能力。
- DGCNN: 该方法在网络的每一层中动态构建图,连接相邻点以更有效地捕获局部几何关系。DGCNN已被证明在分类、分割和部分分割等各种任务上表现异常出色,这得益于其基于图的表示的灵活性。
- Point Tranfformer: 它使Transformer架构适应于点云中局部和全局依赖性的捕获。这种方法通过有效建模点之间的复杂交互,在分类和分割等任务中展示了最先进的性能。
- Point-E: 是最新的基于三维扩散的点云生成模型,它首先使用文本到图像的扩散模型生成单个合成视图,然后使用第二个以生成图像为条件的扩散模型生成三维点云,从而实现从复杂提示生成三维点云。
3.Mesh
网格由顶点、边和面组成,形成多面体形状。顶点是三维空间中的点云,边是连接的顶点对,面由连接三个或更多顶点的边定义。网格之所以受欢迎,是因为它们在简单性和表达能力之间提供了良好的平衡。通过调整顶点和面的数量,它们可以以任意精度近似复杂的几何形状。此外,网格受到图形硬件的良好支持,使其在处理渲染和模拟任务时高效。网格表示的灵活性允许有效计算表面属性,如法线和曲率,这对于真实感渲染和物理模拟至关重要。

- Neural 3D Mesh Renderer: 引入了一种可微渲染器,允许对涉及网格表示的神经网络进行端到端训练。这种可微性使得能够通过基于图像的损失函数直接优化三维网格参数,从而在神经网络中架起二维图像处理与三维几何操作之间的桥梁。
- Pixel2Mesh: 提出了一种从单张RGB图像重建三维网格的端到端网络。该方法将基于图的卷积网络与网格变形框架相结合,使初始椭球体能够逐步细化成详细的三维网格。这种方法证明了深度学习能够从二维输入生成准确且详细的三维形状。
- AtlasNet: t引入了一个使用深度神经网络生成三维网格的框架,将三维表面表示为一系列参数化表面块的集合,这些表面块通过学习并组装成最终网格。这种方法在捕获复杂几何形状方面提供了灵活性,并促进了高效的学习和推理。
- Mesh R-CNN: 将Mask R-CNN框架扩展到处理三维网格预测。它结合基于图像的特征提取和图卷积网络来预测图像中物体的三维形状,在三维形状重建任务中取得了最先进的成果。将图像分割和三维重建集成在一个框架中,体现了利用网格表示进行复杂场景理解的进展。
4.Signed Distance Function (SDF)
符号距离函数(SDF)表示广泛用于表示三维物体的水密形状(water tight shapes,表面完全封闭且没有任何孔洞或裂缝的形状)和表面。SDF通过定义空间中任意点到物体最近表面的距离来编码物体的几何形状,符号表示点是在物体内部(负号)还是外部(正号)。这种表示允许对表面进行平滑和连续的描述。
该领域的一项基础工作是使用SDF进行隐式表面建模,其中表面由SDF的零水平集定义。这种方法能够无缝处理拓扑变化,如表面的合并和分裂,这在涉及流体动力学和可变形物体的模拟中特别有利。
- DeepSDF: 引入了直接从原始数据学习连续SDF的能力,从而能够从不完整和带噪声的观测中实现高保真形状表示和重建。DeepSDF能够捕获精细细节和复杂拓扑结构,在准确性和效率方面优于传统的基于网格和基于体素的方法
- A-SDF: 在关节化形状表示方面, Articulated SDFs (A-SDFs),用于通过分离的潜在空间表示形状和关节化结构来建模关节化形状。通过引入测试时自适应(Test-Time Adaptation),增强了 SDF 在表示上的能力,使得模型可以在测试时进行调整。该研究强调了基于 SDF 方法在捕捉关节化和可变形物体细节方面的多样性和适应性,将 SDF 的实用性从静态形状扩展到了动态模型领域。
- AutoSDF:该方法依赖自回归形状先验,用于高效完成 3D 形状补全、重建和生成。该研究的突出之处在于其处理多模态 3D 任务的能力,同时在针对单一任务优化的现有最先进方法上实现了性能超越。此方法不仅巩固了 SDF 在捕捉复杂几何形状方面的实用性,还展示了深度学习在从大规模数据集中提取和利用形状先验的强大能力。
- SDF‐StyleGAN:将 StyleGAN2 的能力扩展到基于隐式 SDF 的 3D 形状生成。该创新方法通过引入专门针对真实与生成 SDF 值及其梯度的判别器,解决了高质量 3D 几何形状生成的难题,从而显著提升了生成形状的视觉质量和几何精度。
- LAS-Diffusion: 提出了一种基于扩散的框架,并结合了一种新颖的视角感知局部注意机制,重点提升了 3D 形状的局部可控性和泛化能力。该方法有效地利用二维草图图像作为输入,为基于图像条件生成 3D 形状开辟了新途径,能够满足细致的需求和艺术创作的愿景。
5. Neural Radiance Field (NeRF)
神经辐射场 (NeRF) 已成为 3D 表示和视图合成领域的一种革命性方法。该技术通过神经网络对体积场景进行编码,能够从稀疏的输入图像集合中合成复杂场景的新视图。
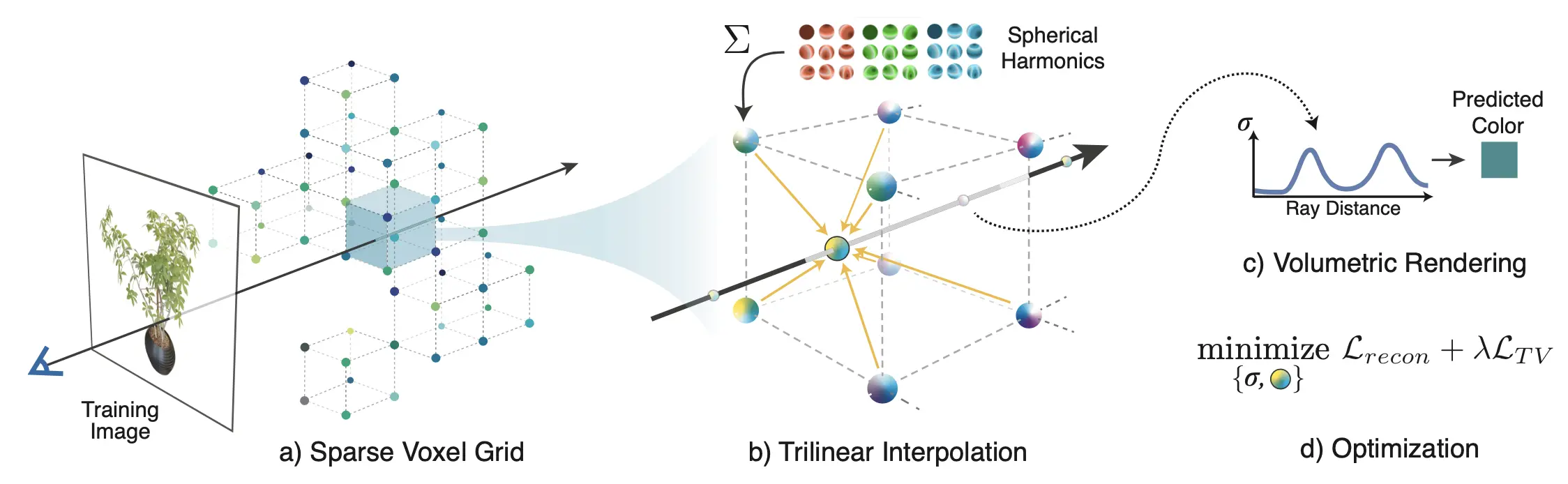
NeRF : 利用全连接深度神经网络,根据空间坐标和视角方向预测空间中某点的颜色和密度。这种方法通过沿场景中的光线对预测值进行积分,从而从新视角渲染出逼真的图像。NeRF 渲染出的图像质量极高,使其成为 3D 计算机视觉和图形学的基础性技术。
- GRAF: 探讨了如何将生成模型与辐射场相结合,以合成一致的 3D 图像。GRAF 利用生成对抗网络 (GAN) 的能力,生成从不同视点观察都保持一致的高质量图像,从而推动了 3D 表示与图像合成的交叉研究。
- NeRF++: 研究了 NeRF 在处理无界场景时的局限性,并提出了改进措施,以增强对复杂几何和深度变化场景的表示能力,从而拓宽了 NeRF 技术的应用范围。
- NeRF–:: 针对相机参数未知的情况,提出了一种同时优化场景表示和相机参数的方法。这一创新使得 NeRF 在更加灵活和不受控的环境中得以应用,提升了其实用性。
- NeRF-W : 将 NeRF 的适用性扩展至非受控和多样化的照片集合。此研究解决了真实世界图像数据集中因光照、天气和遮挡引起的变化问题,从而在不受控数据下实现高质量的视图合成。
- Mip-NeRF :通过引入多尺度表示解决了 NeRF 中的混叠伪影问题。这种方法使渲染更加稳健和准确,尤其是在不同细节和尺度下,从而提升了图像的视觉质量。
- InstantNGP: 关注于优化 NeRF 的训练和推理效率。通过结合基于哈希表的编码和高效的 GPU 计算,InstantNGP 大幅减少了 NeRF 模型的训练时间,使其更适用于实时应用。
- Mip-NeRF 360:引入了一种多尺度表示,能够有效处理反混叠问题和无界场景的复杂性,从而生成更精确和视觉上更令人满意的渲染。
- Plenoxels:是对传统基于神经网络的 NeRF 方法的一次重大创新。Plenoxels 利用稀疏体素网格直接编码辐射场,完全绕过了神经网络的需求,既保留了高质量的视图合成能力,又提升了方法的简单性和效率。
- Zip-NeRF:通过采用网格化结构进行辐射场的高效采样和表示,减少了 NeRF 的计算开销。这种方法不仅加速了渲染过程,还缓解了混叠伪影问题,生成了更清晰和精确的图像输出。
6. 3D Gaussian Splatting
3D Gaussian Splatting(3DGS) 是一种创新的3D场景建模和渲染技术,基于高斯分布来表示场景。3DGS 的核心思想是将场景表示为一组3D高斯分布,这些高斯分布能够高效地近似场景的几何和外观信息。每个高斯分布封装了空间和颜色信息,从而可以实现对表面和纹理的平滑、连续的近似。

相比传统基于 NeRF 的模型,3DGS支持实时渲染,这种实时能力得益于高斯分布的连续性特性,它可以通过基于点的技术和先进的加速结构高效渲染和优化。
- 3D Gaussian Splatting: 首次提出使用 3D 高斯点渲染辐射场,实现了复杂场景的实时渲染。该方法展示了如何高效渲染高斯点,并将其集成到实时应用中,与传统的 NeRF 和体素渲染相比,性能显著提升。
- DreamGaussian: 扩展了 3DGS 的应用,将其与生成模型相结合,用于创建 3D 内容。通过高斯点的高效性,这些方法能够以较低的计算成本生成高质量的 3D 内容。这种生成方法可以合成新的场景和对象,为游戏和电影的内容创作者提供了强大的工具。
- Mip-Splatting解决了 3DGS 中的混叠问题。混叠是由于表示分辨率不足以捕获场景细节而导致的视觉伪影。Mip-Splatting 通过引入分层表示,使用多层次的细节来缓解混叠问题,从而确保渲染在不同尺度下都能保持平滑和细致。
- 4DGS提出了使用可变形 3D 高斯分布来重建动态场景的方法。这种方法能够从单目视频输入中准确建模移动物体和场景的变化,实现高保真的重建。
- Dynamic 3DGS:探讨了动态 3D 高斯分布在场景中跟踪物体的应用。该技术专注于持续动态视图合成,能够在时间维度上连续、一致地跟踪物体。